























Advancements in Artificial Intelligence (AI)
Best Practices for Creating Medical Datasetsand ML are revolutionizing healthcare. According to Forbes, AI, which replicates human intelligence using ML and computer science, is expected to grow by 37.3% annually from 2024 to 2030. In healthcare, Working with medical data using ML, Natural Language Processing (NLP), and computer vision enhances diagnostics and treatment, and creates a niche for AI in patient management. AI analyzes medical images, extracts insights from clinical notes, and aids in surgery, predictive analytics and drug discovery. High-quality medical datasets are crucial for these innovations. This article explores their role, creation, challenges, and future impact in healthcare.
Artificial Intelligence (AI) and Machine Learning (ML) are transforming healthcare, particularly in diagnostics, treatment, and data management. AI-powered imaging tools have shown exceptional accuracy in detecting diseases like cancer. For instance, an AI model in a study outperformed six radiologists in reading mammograms, reducing false positives by 1.2% and false negatives by 2.7%. AI’s tireless analysis capabilities can significantly improve early cancer detection and alleviate the workload of radiologists.
In drug discovery, AI optimizes experiments, highlights promising targets, and enables virtual screening, leading to faster identification of failures and a broader scope of testing. The impact is so profound that the global AI in drug discovery market is projected to reach $4.9 billion by 2028, with a robust annual growth rate of 40.2% from 2024 to 2028.
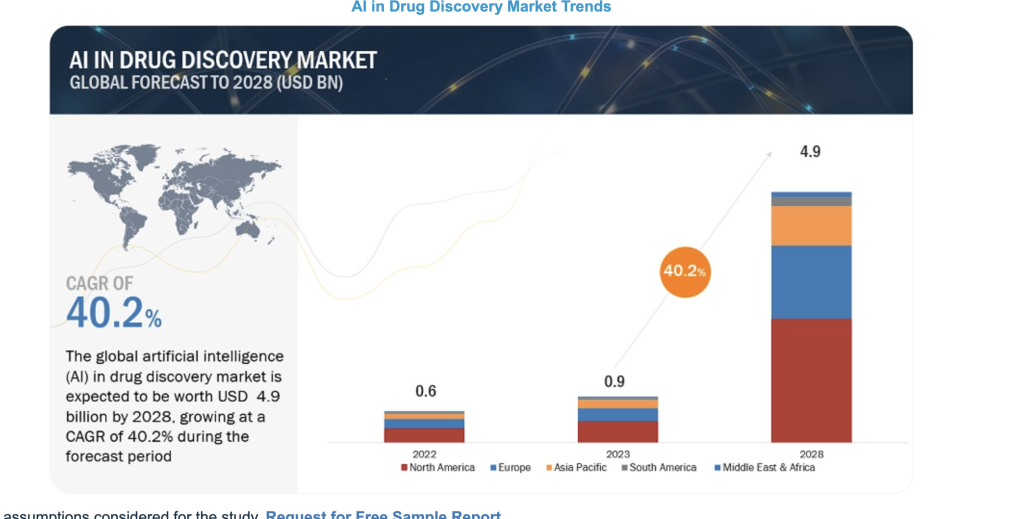
Image source Markets and Markets
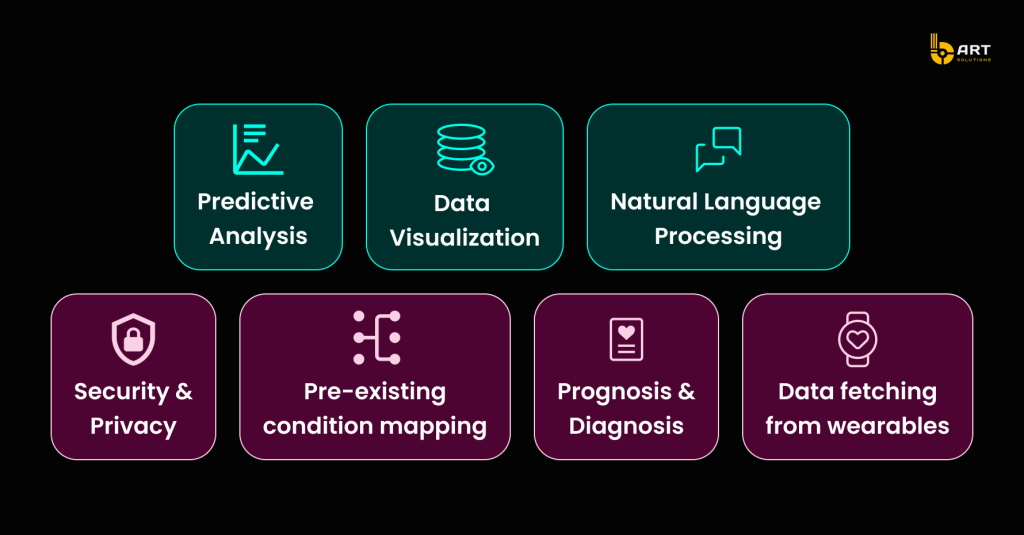
Electronic Health Records (EHR) and Electronic Medical Records (EMR) platforms are also being revolutionized by AI. Physicians currently spend about 62% of their time per patient reviewing medical records. The introduction of AI systems to organize patient health records has shown promising, it helps to save an average of 18% of the time, without sacrificing accuracy.
Here is a visualization of how AI EHR/EMR solutions streamline the workflow for doctors, making data retrieval and analysis more efficient.
Personalized medicine is transforming healthcare by focusing on individual differences to improve treatment outcomes. By integrating a patient’s genetic information, lifestyle, and environmental factors, healthcare professionals can create targeted interventions tailored to each person. This approach ensures that care is more effective and specific to each patient’s needs.
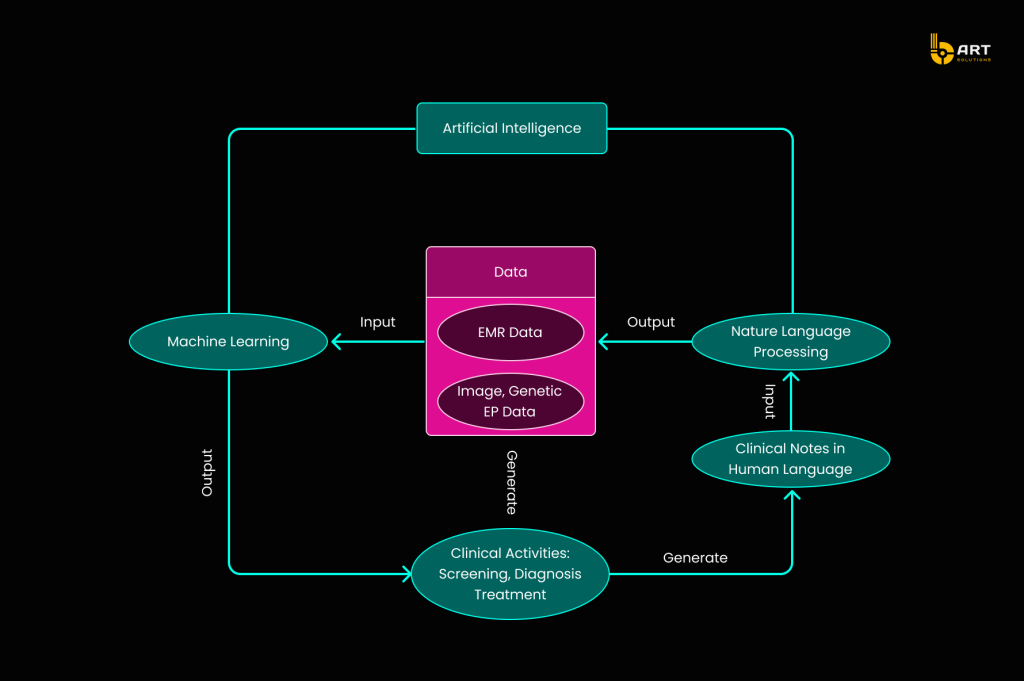
While AI has the potential to elevate every aspect of healthcare, its implementation is complex. The roadmap for integrating AI into healthcare begins with clinical data production, advances through data enrichment using Natural Language Processing (NLP), and culminates in ML analysis. This process transforms raw data into actionable insights that support and enhance clinical practice.
The Importance of Medical Datasets
Datasets are the bedrock on which AI models are trained, validated, and tested. High-quality healthcare datasets ensure the accuracy, reliability, and efficiency of industry-specific software solutions
What are Healthcare Data Sets?
A data set in the field of health and patient care is a collection of information sets made up of different items, which can be processed collectively by a computer. It can be a single database table or a statistical data matrix, ranging from a few items to vast amounts of data.
Healthcare data sets specifically these may include medical records, measurements, financial data, statistical figures, demographic details, and insurance information, sourced from healthcare outlets.
The Role of Healthcare Data Sets
Given that healthcare data originates from diverse sources, standardizing it is essential to maximize its value and facilitate collaboration among healthcare providers, researchers, and government entities.
In the US, the exchange of healthcare data is strictly regulated to protect patients’ personal health information (PHI). Regulations such as HITRUST and HITECH are dedicated to data interchange standards, including shared encoding specifications, medical templates for organizing information, document architectures, and information models.
The main parameters critical for building effective data sets in healthcare domain include:
Data Quality
Accuracy: Ensures that the data correctly reflects real-world conditions and events.
Completeness: Involves having all necessary data points available without missing values.
Consistency: Maintains uniformity in data across different sources and time periods.
Poor-quality data can lead to erroneous conclusions and potentially harmful decisions. Thus, meticulous attention to data quality is essential.
Data Privacy and Ethics
- Privacy. Robust security measures prevent unauthorized access and breaches. Protected Health Information (PHI) resides in documents like emails, clinical notes, test results, or CT scans. Diagnoses and prescriptions become subject to HIPAA when linked to identifiers such as names, dates, contacts, and other elements by which a particular patient may be identified. There are 18 HIPAA identifiers, and even one is enough to make an entire document PHI that can’t be disclosed to third parties.
- Ethics and Transparency. Ensuring that data is obtained with informed consent is vital to respecting patients’ rights and autonomy. Maintaining transparency about how the data will be used, stored, and shared is essential to build and sustain trust. However, ethical AI involves not just the end use but also the foundational principles on which it is built.
Diversity and Representation
- Inclusivity. To avoid bias in AI models, datasets must be diverse and representative of various populations. There are credible concerns that many datasets fall short in this regard, leading to ‘Health Data Poverty.’ Ensuring inclusivity also addresses issues in data collection and categorization. For example, a dataset might have proportional representation of an ethnic group but still exhibit disparities if individuals from that group are misdiagnosed more frequently.
- Equity. Achieving equitable outcomes requires more than just data diversity. Even with proportional representation, biases can still persist. For instance, individuals from an ethnic group might be well-represented but still face a higher likelihood of misdiagnosis, leading to skewed insights. Therefore, it is essential to take into account the limitations of data collection and accuracy, especially concerning minoritized and underserved groups.
Best Practices for Creating Medical Datasets

Data Collection
High-quality healthcare datasets are the cornerstone of developing effective ML models. While it is possible to compile datasets from existing sources, this often leads to suboptimal performance and fails to address specific research questions. To ensure datasets used in medical research maintain high standards, consider the following guidelines.
- Source Verification. Using data from credible and authorized providers is critically important for maintaining the integrity and accuracy of healthcare data sets. Verifying the source helps to confirm that the information is reliable and trustworthy, which is fundamental for any subsequent analysis or model training.
- Comprehensive Coverage. Collecting a diverse range of data types, such as clinical notes, medical images, and patient demographics, provides a holistic view of patient health. Comprehensive coverage helps AI models handle a variety of medical scenarios and deliver more accurate predictions.
- Patient Consent. Obtaining clear and informed consent from patients is vital for ensuring transparency and trust in the use of their private information. This process not only complies with legal and ethical standards but also reassures individuals that their privacy is respected.
Data Cleaning
Raw medical data often contains errors, inconsistencies, and duplications that can distort AI model results. Data cleaning ensures the dataset is reliable and valid.
- Check for Duplicates. Duplicate entries can occur when information is collected from multiple sources. For instance, a patient’s medical records might be duplicated if gathered from different hospital departments. Removing these redundancies prevents the model from learning incorrect patterns.
- Remove Outliers. Outliers are points that deviate significantly from the rest of the dataset and can arise from errors or anomalies, such as an abnormal spike in lab test outcomes due to a technical malfunction. Identifying and removing outliers ensures the model learns from representative and accurate information.
- Fix Structural Errors. Structural errors encompass inconsistencies such as different spellings or mislabeling within the dataset. For instance, ‘Diabetes‘ and ‘diabetes‘ should be treated as the same category. Correcting these errors ensures a more accurate class distribution and improves the reliability of the analysis.
- Check for Missing Values: Missing data can result in incomplete training and inaccurate models. Handling missing values can involve either removing the affected data points or filling in the gaps using methods like mean imputation or predictive modeling. For example, if a patient’s age is missing, it could be estimated based on other available demographic information.
Data Labeling
Labeling a healthcare data set involves detecting and tagging samples to assign meaningful classes or labels. Accurately labeling patient records, medical images, or genomic data with specific diagnoses or conditions ensures that AI models can learn effectively. This process is vital for developing robust and reliable AI-driven systems capable of making accurate predictions and supporting clinical decision-making.
- Create a Gold Standard. Engage data scientists and healthcare experts to label a subset of medical data with high accuracy. For example, in a dataset containing medical imaging data, a professional radiologists can precisely label a subset of images with accurate diagnoses. Then it will guide less experienced annotators, ensuring that the entire dataset maintains a high level of accuracy and consistency.
- Avoid Overly Complex Labels. Simplifying the labeling scheme helps maintain clarity and consistency. In the task of labeling patient conditions, using broader categories like “Hypertension” and “No Hypertension” instead of overly granular labels such as “Severe Hypertension,” “Moderate Hypertension,” “Mild Hypertension,” and “Borderline Hypertension” reduces confusion among annotators and makes the dataset more manageable for training AI models.
- Use Multipass Labeling. Involve multiple annotators to label the same data points. This method helps establish consensus and improves the overall quality of the labeled data, despite being time-consuming and resource-intensive.
- Implement a Review System. Establish a review process where labeled data is checked for accuracy and consistency by independent annotators or through automated checks. This feedback mechanism helps identify areas for improvement and secures high-quality labeling.
Data Preprocessing
- Normalization: Normalizing the data to a standard format ensures consistency across the dataset, which is necessary for accurate analysis and model training.
- Anonymization. Stripping identifiable information from the dataset protects patient privacy and guarantees compliance with privacy regulations. Anonymization makes the data safe for analysis and sharing, fostering a secure environment for medical research.
- Balancing. Addressing any imbalances in the dataset prevents bias in predictive modeling. Balancing allows the AI models to learn fairly and accurately, leading to more equitable outcomes in medical predictions and decision-making.
Quality control is mandatory when creating a medical dataset, as inaccurate results can lead to dangerous outcomes. Reliability is the key, so double-check all results obtained from datasets before making any inferences or decisions based on them.
Navigate the Complexities of Healthcare Datasets
Utilizing data sets in healthcare software provides practitioners and administrators with valuable insights into patient health, treatment outcomes, and other important clinical metrics. However, despite the clear potential benefits of leveraging such data, there are significant challenges and limitations that must be addressed to use these technologies responsibly.
Data Quality and Quantity
ML models thrive on high-quality data, but poor data leads to unreliable predictions. In healthcare, patient records are the primary source of data for training diagnostic models. However, incomplete or inaccurate data can result in erroneous predictions, posing serious risks to patient health.
Overfitting and Underfitting
Balancing model complexity can be difficult. Overfitting occurs when a model is too complex, capturing noise in the training dataset and leading to poor performance. Conversely, underfitting happens when a model is too simplistic, failing to identify the underlying patterns.
Interpretability and Explainability
Many ML models operate as “black boxes,” lacking interpretability and explainability. This opacity makes it challenging to understand the reasoning behind their conclusions, which is problematic in medical applications, where knowing the decision-making process is essential for trust and validation.
Bias and Fairness
Models can inadvertently inherent biases from their training data, leading to unfair or discriminatory outcomes. For example, diagnostic algorithms must be checked to avoid bias against certain demographic groups, ensuring fair treatment for all patients.
Computational Resources
Training large ML models requires substantial computational resources. Advanced diagnostic models demand significant computing power, raising concerns about cost and environmental impact.
Model Selection
Choosing the right model for a specific problem can be perplexing. The appropriate model depends on the data type, the nature of the problem (classification, regression, clustering), and the desired output. For instance, convolutional neural networks (CNNs) are well-suited for medical image analysis, while recurrent neural networks (RNNs) are ideal for processing EHR data sets.
Data Privacy and Security
Ensuring data privacy and security in each and every medical dataset is a complex but essential task. Protecting patient information requires adherence to stringent privacy regulations and the implementation of robust security measures such as data anonymization and encryption. Additionally, access to datasets should be restricted to authorized personnel only.
Ethics
In addition to safeguarding data privacy and security, it is crucial to consider the ethical implications of using any single medical dataset, regardless of its complexity, in AI and ML initiatives Healthcare organizations are obligated to make sure that insights derived from these datasets do not result in discriminatory outcomes based on factors such as race or gender. Such outcomes would violate ethical standards set by professional bodies like the American Medical Association (AMA) and The World Medical Association (WMA).
Understanding the Limitations of Machine Learning in Healthcare

Lack of Genuine Comprehension
ML models lack common-sense understanding and make predictions based only on statistical patterns. A diagnostic model may identify patterns in symptoms without truly understanding the underlying disease. Furthermore, ML models are highly dependent on the data they are trained on and cannot provide insights beyond their training set.
Model Robustness
ML models can be fragile and sensitive to minor changes in input data, which is a significant issue in healthcare where data may be noisy or incomplete. Ensuring model robustness through rigorous testing and validation is essential.
Through careful consideration and strategic implementation, the healthcare industry can leverage machine learning to achieve significant advancements while maintaining high standards of quality, fairness, and security.
However, decisions shouldn’t be made based solely on insights from AI/ML models. Involve experts in reviewing the output results. Medical conclusions must be informed by human expertise and analysis of the available evidence.
Exploring the Future of Medical Datasets

Healthcare data sets are poised to revolutionize the industry by providing the foundation for advanced AI and machine learning (ML) applications. These technologies promise to enhance diagnostic accuracy, personalize treatment plans, and improve patient outcomes. This section explores emerging technologies, and the trends driving this transformation.
Emerging Technologies in Medical Data Management
Several modern technologies are enhancing the collection, storage, and analysis of medical datasets:
Blockchain: Ensures the security and integrity of medical data by providing a decentralized and tamper-proof ledger for health records.
Internet of Medical Things (IoMT): Integrates medical devices and wearables to continuously collect patient data, providing real-time monitoring and analysis.
Federated Learning: Allows AI models to be trained on decentralized data sources without compromising patient privacy, enabling collaboration across institutions.
Key Trends Shaping the Future of Medical Datasets
Interoperability: Efforts to standardize and harmonize medical data formats make datasets easily shared and integrated across different healthcare systems and platforms.
Data Privacy and Security: With the increasing reliance on digital health data, improved measures to protect patient privacy and secure sensitive information are paramount.
Regulatory Compliance: Adherence to regulations such as GDPR and HIPAA is essential for the ethical use of healthcare datasets in AI and ML applications.
Patient Empowerment: Patients are becoming more involved in managing their health data, leading to the development of platforms that give individuals greater control over their medical information.
Open Source Medical Datasets for Machine Learning

General and Public Health Datasets
data.gov: This platform focuses on US healthcare data, easily searchable with multiple parameters, aiding in improving public health.
WHO: Provides global health datasets with a user-friendly search function, offering valuable insights into health priorities worldwide.
Re3Data: Hosts data across over 2,000 research subjects, categorized for easy searching, though some datasets require fees or memberships.
Human Mortality Database: Offers data on mortality rates, population figures, and health statistics for 35 nations.
CHDS (Child Health and Development Studies): Investigates intergenerational disease transmission, encompassing genomic, social, environmental, and cultural factors.
Merck Molecular Activity Challenge: Promotes machine learning in drug discovery by simulating interactions between various molecules.
1000 Genomes Project: Contains sequencing data from 2,500 individuals across 26 populations, accessible via AWS.
Medical Image Datasets
OpenNeuro: Shares a variety of medical image datasets, including MRI, MEG, EEG, and PET data, from 19,187 participants.
OASIS: Provides free neuroimaging data for scientific research, including MR and PET sessions.
Alzheimer’s Disease Neuroimaging Initiative: Includes MRI and PET images, genetic information, cognitive tests, and biomarkers to study Alzheimer’s disease.
Hospital Datasets
Provider Data Catalog: Offers datasets on various healthcare services, including dialysis facilities, physician practices, and home health services.
Healthcare Cost and Utilization Project (HCUP): A nationwide database tracking healthcare utilization, access, charges, quality, and outcomes in US hospitals.
MIMIC Critical Care Database: Developed by MIT, this dataset includes de-identified health data from over 40,000 critical care patients.
Cancer Datasets
CT Medical Images: Features CT scans of cancer patients, focusing on contrast, modality, and patient age.
International Collaboration on Cancer Reporting (ICCR): Standardizes cancer reporting to improve data quality and comparability.
SEER Cancer Incidence: Provides cancer data segmented by race, gender, and age, facilitating research on cancer incidence and survival rates.
Lung Cancer Data Set: Contains data on lung cancer cases dating back to 1995, useful for studying trends and developing diagnostic tools.